
GMOインターネットがNVIDIA B300 GPUの性能を検証
GMOインターネットグループのGMOインターネット株式会社は、「GMO GPUクラウド」における「NVIDIA H200 Tensor コアGPU」(H200 GPU)と「NVIDIA HGX B300 AI インフラストラクチャ」(B300 GPU)の性能特性を検証した結果を発表しました。
今回の検証は、生成AIの開発から運用までの実用性と演算性能の両面を評価することを目的としています。具体的には、大規模言語モデル(LLM)の学習ベンチマーク、vLLM bench throughputによる推論ベンチマーク、HPL Benchmarkによるベンチマークの3つを実施しています。
実施したベンチマークの概要
1.大規模言語モデル(LLM)の学習ベンチマーク
LLMを実際に学習(ファインチューニング)させ、目標とする品質に到達するまでの学習時間を測定するベンチマークです。学習効率と演算速度を評価する指標として活用されます。

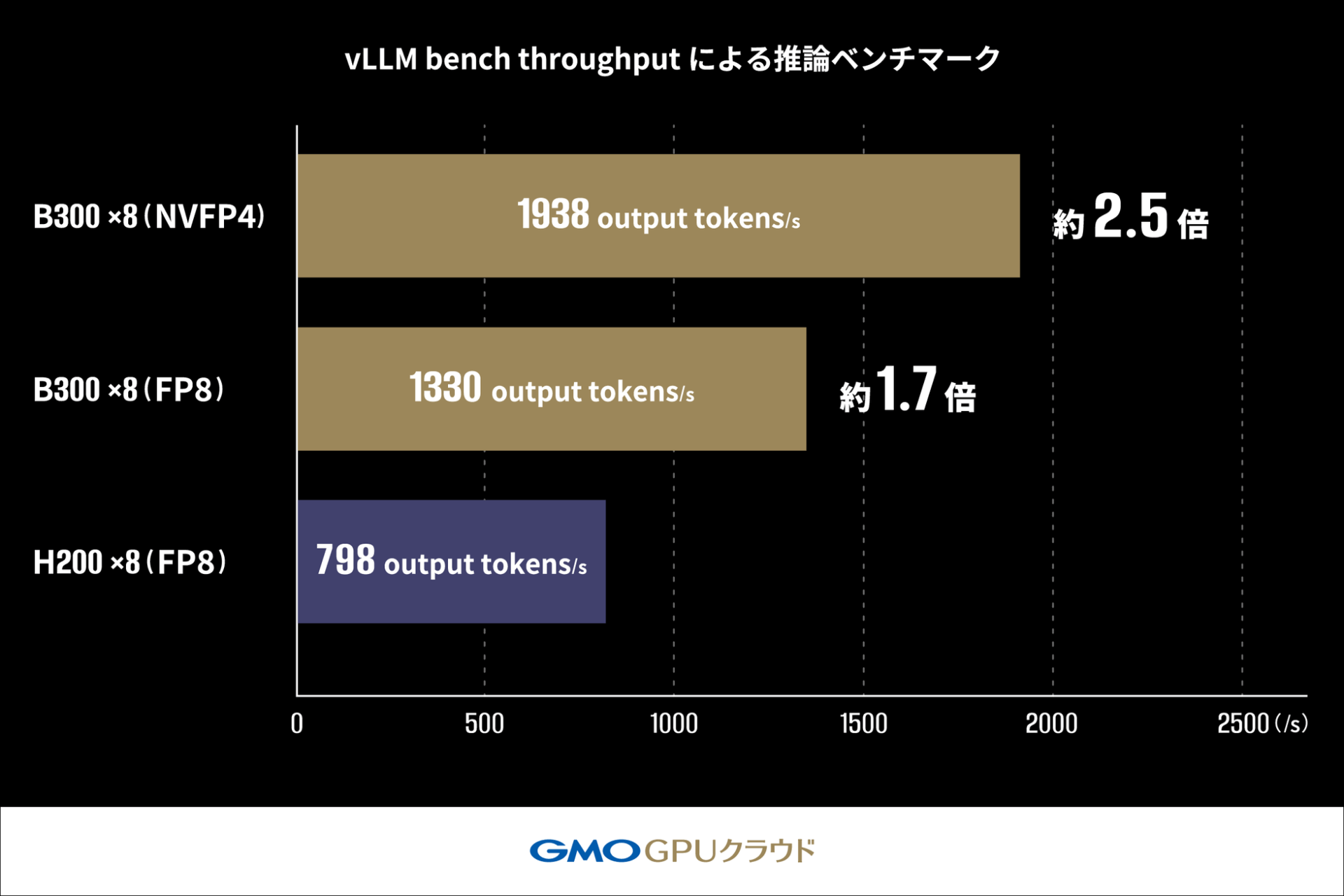
2.vLLM bench throughputによる推論ベンチマーク
LLM推論のバッチ処理を高速に実行し、1秒あたりに生成できる出力トークン数(output tokens/s)など、最大スループットを測る推論性能ベンチマークです。単位時間あたりに生成可能なトークン量を評価します。(トークン量とは、文章を処理するための最小単位のこと)

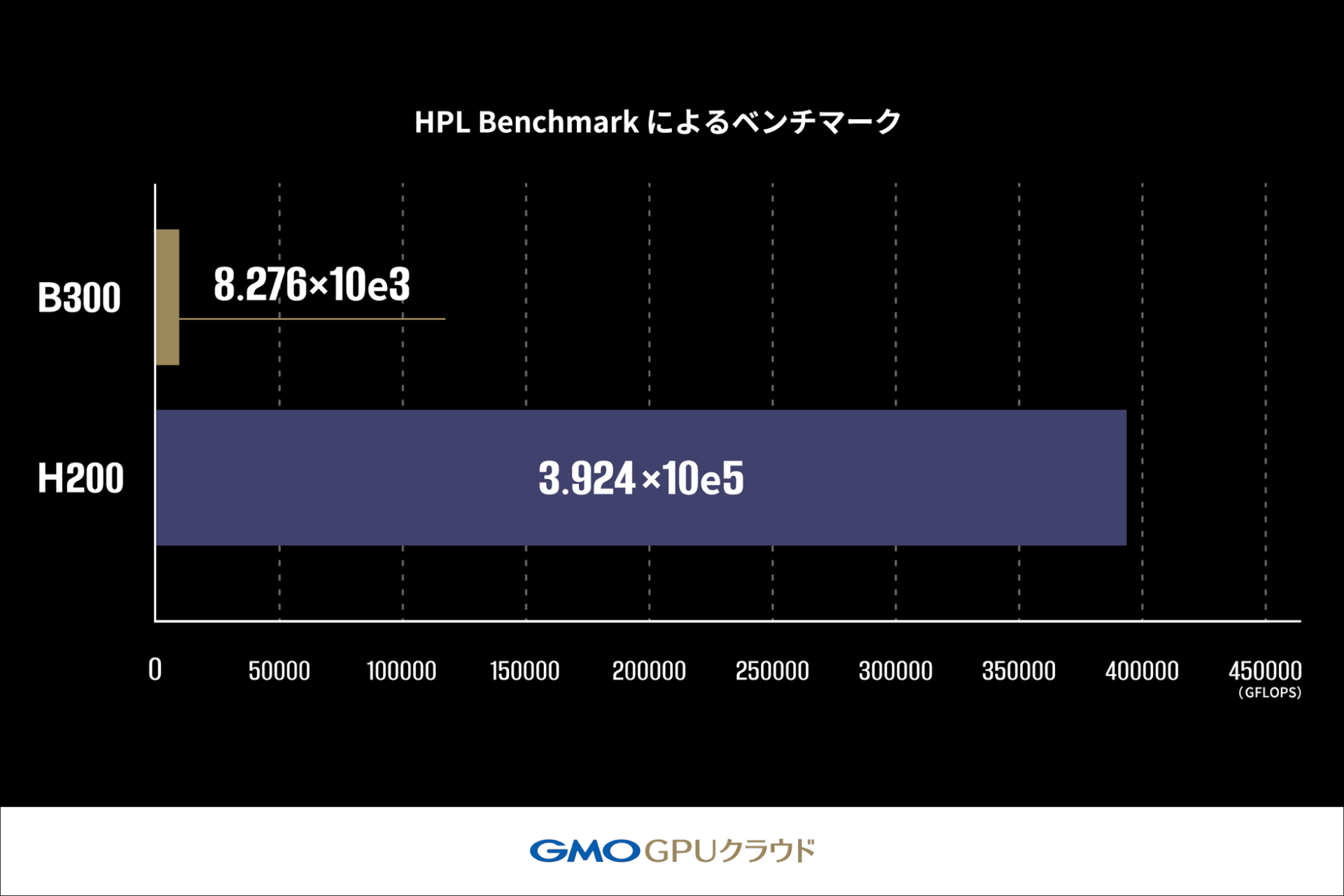
3.HPL Benchmark によるベンチマーク
密行列の連立一次方程式を解く処理を通じて、浮動小数点演算性能(GFLOPS)を測定するHPC系の基礎計算性能ベンチマークです。科学技術計算における複雑で精密な数値計算の性能を測定します。
ベンチマークテストの結果
検証の結果、生成AIワークロードにおいて、B300 GPUはH200 GPUと比較して学習で約2倍、推論では約2.5倍の処理性能を発揮することが確認されました。
一方で、スーパーコンピュータの性能評価に用いられるHPL Benchmarkでは、B300 GPUはH200 GPUの2.1%(約47分の1)の性能に留まりました。これは、B300 GPUが生成AIワークロードに特化した高い性能を持つ一方、科学技術計算など計算結果の正確性を重視するユースケースにおいては、H200 GPUが依然として適している可能性を示唆しています。
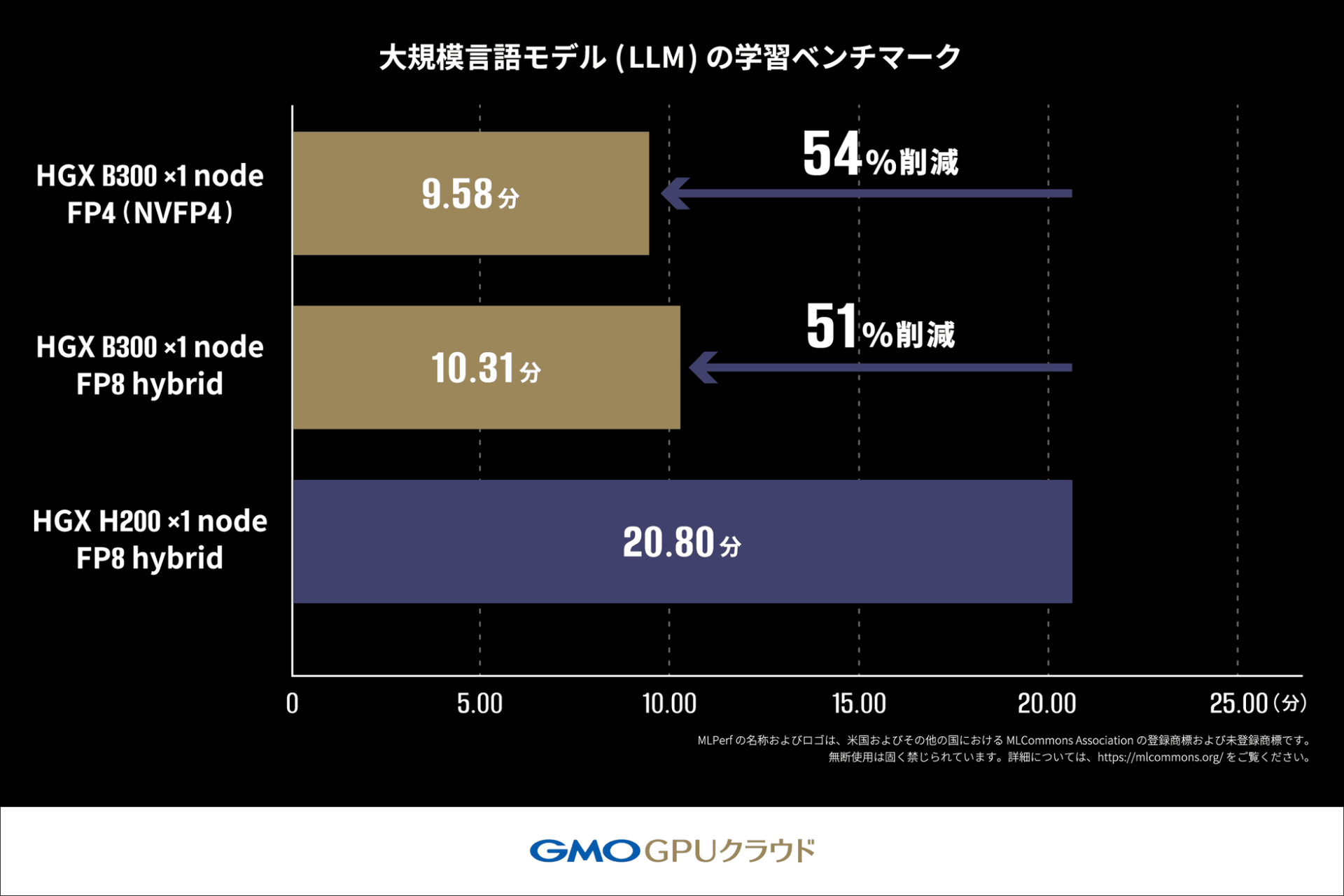
大規模言語モデル(LLM)の学習ベンチマーク詳細
MLPerf (R) Training v5.1のルールに従い、Llama2 70Bモデルを用いてLoRAファインチューニングにかかる学習時間を測定しました。H200 GPU搭載機材では20.80分かかっていた学習時間が、B300 GPU搭載機材では10.31分で完了し、約2倍の速度で処理が完了しました。
さらに、NVIDIA Blackwellアーキテクチャより新たに対応したFP4を用いた測定では、FP8 hybridを使用した学習よりも短い時間で処理が完了しており、FP4の高い演算性能を活かすことで学習速度の向上が期待できます。(FP4、FP8 hybridとは、データの表現方法に関する技術のこと)
vLLM bench throughputによる推論ベンチマーク詳細
vLLMのOffline Throughput Benchmarkを用い、Llama-3.1-405B-Instructモデルの推論スループットを測定しました。詳細な結果については、今後の発表が期待されます。
 Ms.ガジェット
Ms.ガジェット最後までお読みいただきありがとうございました!
- 本記事の評価は当サイト独自のものです。
- 特段の表示が無い限り、商品の価格や情報などは記事執筆時点での情報です。
- この情報が誤っていても当サイトでは一切の責任を負いかねますのでご了承ください。
- 当サイトに記載された商品・サービス名は各社の商標です。
- 本記事で使用している画像は、メディアユーザーとしてPR TIMESより提供されたプレスリリース素材を利用しています。