

COM-HPC Client プラットフォームの性能向上
コンガテックは、COM-HPC Client Size C コンピューター・オン・モジュール「conga-HPC/cBLS」を発表しました。このモジュールは、ハイパフォーマンスのP-コアのみを搭載した、新しいインテル Core Series 2を採用し、最大12個の同一P-コアを搭載します。最大192 GBのRAMをサポートし、先進的なI/OテクノロジーやAIアクセラレーターカード向けの高帯域幅接続を実現する42本のPCIeレーンを提供します。
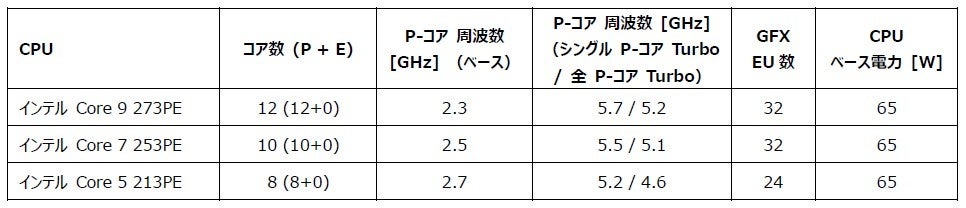
このモジュールは、多数のデータストリームを並列処理する必要がある決定論的なハイエンドアプリケーション向けに特別設計されています。試験・計測、メディカルイメージング、スマートグリッド、エネルギーシステム、ロボティクス、産業用プロセスオートメーションなど、ワークステーションクラスのサイズでサーバークラスのパフォーマンスが要求されるエッジコンピューティングアプリケーションに最適です。
最大5.7 GHzで決定論的ハイエンド組込みコンピューティングを実現
新しいモジュールは、統一された命令セットを備えるホモジニアスCPUアーキテクチャーで、完全に決定論的な動作を実現する低レイテンシシステムの開発を簡素化します。ハイパフォーマンスでありながらコスト効率の高いLGAプロセッサーを搭載したconga-HPC/cBLSは、最大5.7 GHzのCPU周波数で最大のコンピューティング能力を発揮します。

このパフォーマンスは、据置型あるいはモバイル型テストベンチのデータロガーのほか、ロボットやCNCマシン、自動生産ライン向けの高精度リアルタイム制御システム、そしてAIを使った品質検査システムなどのアプリケーションに直接メリットをもたらします。conga-HPC/cBLSは、モジュラーアーキテクチャーであることに加えて、高性能ソケットによる簡単なモジュール交換により、将来へのアップグレードパスを提供します。
 Ms.ガジェット
Ms.ガジェットエッジAI向けの優れたAI推論性能
アプリケーションは、最大32個の実行ユニットを備えた内蔵のインテルUHDグラフィックスによる強力なAIアクセラレーション機能の恩恵も受けられます。インテルディープラーニング・ブーストとVector Neural Network Instructions(VNNI)をサポートし、エッジでの効率的なAI推論を可能にします。4つのSO-DIMMソケットにより最大192 GBのECCメモリーを搭載することができ、GPGPUワークロードやデータ集約型エッジアプリケーションをさらに高速化します。

最後までお読みいただきありがとうございました!
- 本記事の評価は当サイト独自のものです。
- 特段の表示が無い限り、商品の価格や情報などは記事執筆時点での情報です。
- この情報が誤っていても当サイトでは一切の責任を負いかねますのでご了承ください。
- 当サイトに記載された商品・サービス名は各社の商標です。
- 本記事で使用している画像は、メディアユーザーとしてPR TIMESより提供されたプレスリリース素材を利用しています。